Recent comments in /f/MachineLearning
Philpax t1_j7ty2l1 wrote
Philpax t1_j7ty0tj wrote
Reply to comment by VectorSpaceModel in What are the best resources to stay up to date with latest news ? [D] by [deleted]
Eh, I still watch the videos but it's clear that the audience has shifted. They're often skint on details and come out a while after the initial release of a paper. They're great for showing people not in the field what's going on, though :)
CampfireHeadphase t1_j7txox9 wrote
Reply to comment by Cantmentionthename in [D] Are there emergent abilities of image models? by These-Assignment-936
Similarly to how a zipped email archive could be called generative communication
clauwen t1_j7txja0 wrote
Reply to comment by SnooHesitations8849 in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
You really have to wonder why everybody uses torch and tf2 then. Stupid trillion dollar companies, could just run everything on cpu, if they could only hire C++ devs. Billions of dollars down the drain, really unlucky.
CeFurkan OP t1_j7txh8r wrote
Reply to comment by Fit_Schedule5951 in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
thank you so much
i tested with model = pretrained.dns64().cuda()
is this their best pre trained mode?
Fit_Schedule5951 t1_j7twyx9 wrote
Reply to comment by CeFurkan in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
https://github.com/facebookresearch/denoiser
Use the pretrained model on your recordings
nielsrolf t1_j7twdn2 wrote
Reply to comment by These-Assignment-936 in [D] Are there emergent abilities of image models? by These-Assignment-936
I thought about it again, and another candidate is all LLM capabilities: if you prompt it for "a screenshot of a python method that does xyz" the best solution would be an image that contains working code.
CeFurkan OP t1_j7tvbny wrote
Reply to comment by logsinh in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
thanks i made it work
however i got out of memory error on RTX 3060 - 12 GB vram
it is like a joke :/
{kind=link}
mr_birrd t1_j7tu7zt wrote
Reply to comment by [deleted] in What are the best resources to stay up to date with latest news ? [D] by [deleted]
Maybe also BERT for 1 word answers to counter the neverding answers from ChatGPT
logsinh t1_j7tu0x1 wrote
Reply to comment by CeFurkan in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
Just download the checkpoint and use the command at Inference session. sr should be 16000
CeFurkan OP t1_j7ttvbm wrote
Reply to comment by logsinh in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
>audio super-resolution
thank you so much for answers and testing
any idea to get super resolution ? or my only option is mindslab-ai/nuwave2 ?
mr_house7 t1_j7tt7ki wrote
Reply to comment by sonofmath in [D] List of RL Papers by C_l3b
Thank you so much for all your answers.
mongoosefist t1_j7tt6a2 wrote
Emergent behaviour is called such because we don't yet have the ability to predict it, we can only observe it and deduce where it emerged after the fact. SO, the fact that you can't wrap your head around what such an ability would look like makes perfect sense!
If we're speculating I'd put my money on /u/ID4gotten 's answer. I bet one of these models starts integrating some intuition of physical laws.
logsinh t1_j7tsvku wrote
Reply to comment by CeFurkan in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
Anyway, here is the denoised audio of your example speech: https://www.sndup.net/pbxf/. There is no improvement, your best bet is audio super-resolution.
Input: Speech MOS: 4.259 Noise MOS: 4.369 Overall MOS: 3.927
Output: Speech MOS: 4.263 Noise MOS: 4.403 Overall MOS: 3.947
akshaysri0001 OP t1_j7ts2wg wrote
Reply to comment by Kthulu120 in [D] Which is the fastest and lightweight ultra realistic TTS for real-time voice cloning? by akshaysri0001
After some training, Yes!
CeFurkan OP t1_j7trlei wrote
Reply to comment by logsinh in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
their example really good improvement but do i need training for that?
opened an issue thread but not much hope : https://github.com/mindslab-ai/nuwave2/issues/11
CeFurkan OP t1_j7tr5at wrote
Reply to comment by logsinh in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
yes i had tried some options obs back in time. it was probably noise gate. even i forgotten it.
thank you so much for reply gonna test that repo now
logsinh t1_j7tqjmm wrote
Reply to comment by CeFurkan in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
The audio is a bit distorted possibly due to noise gating. I don't see too much noise, so maybe noise reduction is not what you need. The audio has 8 kHz bandwidth (16 kHz sample rate), maybe you may try to use an audio super-resolution network such as https://github.com/mindslab-ai/nuwave2 to increase the audio bandwidth.
Initial-Image-1015 t1_j7tqegx wrote
Since there are so many subfields and subsubfields, each of which with an overwhelming amount of research, pick the domain you're interested in an follow the authors of the most relevant papers in that domain on Twitter. Over time, you will naturally find more and more related authors to also follow.
For the other domains, general newsletters give good overviews.
programmerChilli t1_j7tpwd7 wrote
Reply to comment by pommedeterresautee in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
Lots of things. You can see a flamegraph here: https://horace.io/img/perf_intro/flamegraph.png (taken from https://horace.io/brrr_intro.html).
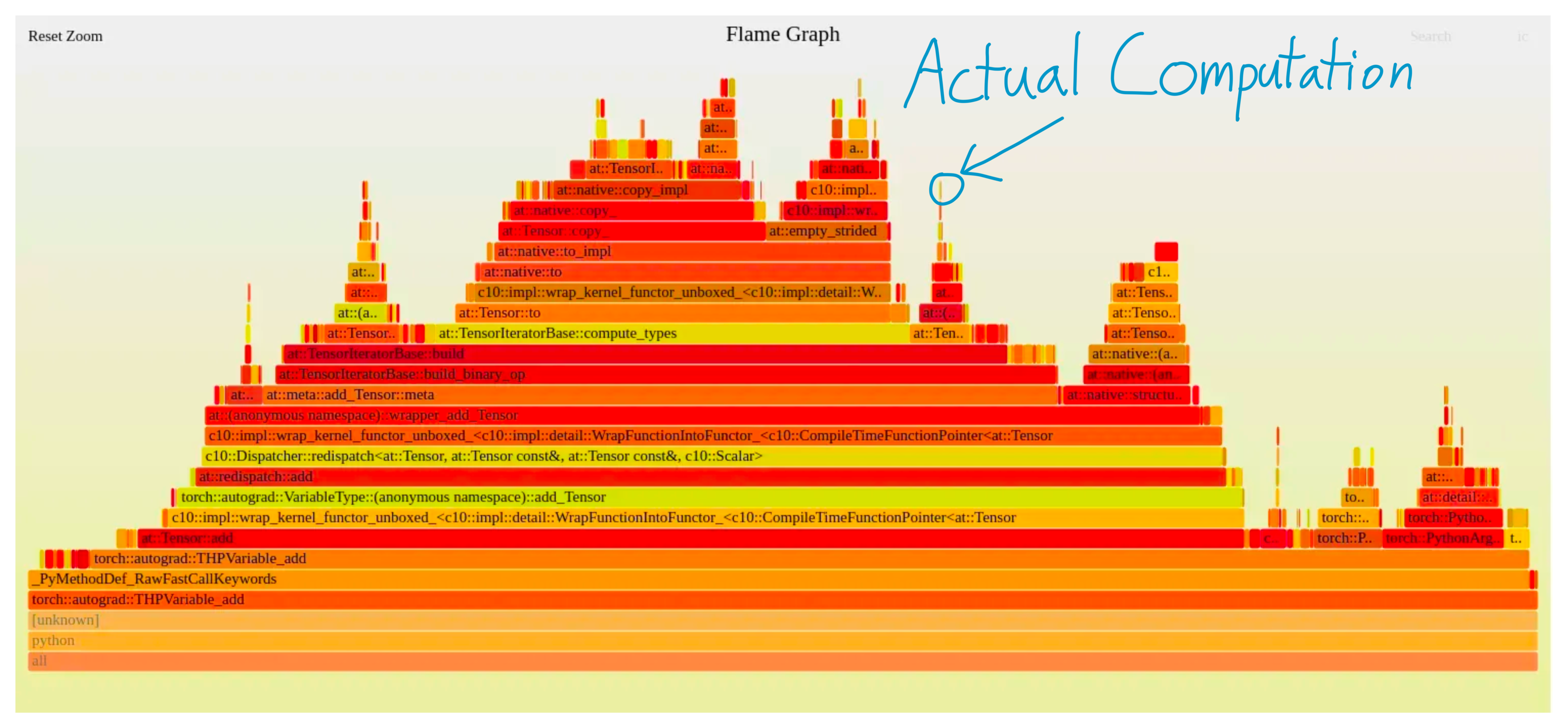{kind=link}
Dispatcher is about 1us, but there's a lot of other things that need to go on - inferring dtype, error checking, building the op, allocating output tensors, etc.
pommedeterresautee OP t1_j7tp663 wrote
Reply to comment by programmerChilli in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
I guess you better know than me :-)
Which part? The dispatcher thing or it's spread on several steps?
programmerChilli t1_j7toust wrote
Reply to comment by pommedeterresautee in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
> The Python layer brings most of the PyTorch latency.
This actually isn't true - I believe most of the per-operator latency come from C++.
JackDT t1_j7toqp1 wrote
This is amazing. The warmup time is annoying but 2.5X is actually fast enough to use for a live stream now. I'll wait 10 minutes if I need to!
CeFurkan OP t1_j7toh7z wrote
Reply to comment by jeanfeydy in [D] Are there any AI model that I can use to improve very bad quality sound recording? Removing noise and improving overall quality by CeFurkan
i tested and 0 improvement for this audio : https://youtu.be/2zY1dQDGl3o
test from here : https://audo.ai/noise-removal
blackkettle t1_j7tyq1r wrote
Reply to [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
This is very interesting, thanks for sharing! Do you have any more detail on RTF vs Accuracy curves? Also did you run this on any other data sets? Librispeech - even the “other” pieces is very clean, simple data from an acoustic and linguistic standpoint.
It would be really interesting to see how well this holds on noisy spontaneous speech like conversations.