Recent comments in /f/MachineLearning
Advanced-Hedgehog-95 t1_j5es27r wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
Watermark may be useful in academic context but why should a company care?
I also wonder what happens to hundreds of writing support apps that are built upon these GPT models.
BitterAd9531 t1_j5erse4 wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
Won't work in the long term. OpenAI might have been the first one to release, but we know other companies have better LLMs and others will catch up soon. When that happens, models without watermarks will be released and people who want output without a watermark will use that model.
And even if you somehow force all of them to implement a watermark, it would be trivial to combine outputs of different models to circumvent it. Not to mention that slight rewrites by a human would probably break most watermarks, the same way they break the current GPT detectors.
new_name_who_dis_ t1_j5ern6t wrote
Reply to comment by JackandFred in [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
How do you detect text produced by GPT? Is there like open source code?
[deleted] t1_j5ermam wrote
flinsypop t1_j5erlpw wrote
Reply to comment by AmputatorBot in [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
Good bot.
adt t1_j5erdiz wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
Already in the works (Scott Aaronson is a scientist with OpenAI):
>>we actually have a working prototype of the watermarking scheme, built by OpenAI engineer Hendrik Kirchner. It seems to work pretty well—empirically, a few hundred tokens seem to be enough to get a reasonable signal that yes, this text came from GPT.
>Now, this can all be defeated with enough effort. For example, if you used another AI to paraphrase GPT’s output—well okay, we’re not going to be able to detect that. On the other hand, if you just insert or delete a few words here and there, or rearrange the order of some sentences, the watermarking signal will still be there. Because it depends only on a sum over n-grams, it’s robust against those sorts of interventions.
https://scottaaronson.blog/?p=6823
drewkungfu t1_j5erafj wrote
Reply to comment by ardula99 in ChatGPT is not all you need [R] by EduCGM
I think there was major word choice failures that perhaps auto-correct spell help mask.
Here my attempt to fix:
“This work paper consists on an
attempts to describe in a concise way the min models are and sectors ^of ^industry ^jobs that are affected by generative AI.
EmmyNoetherRing t1_j5er3xp wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
I’d heard they had added one, actually. Or were planning to— the concern they listed was they didn’t want the model accidentally training on its own output, as more of its output shows up online.
I have to imagine this is a situation where security by obscurity is unavoidable though, so if they do have a watermark we might not hear much about it. Otherwise malicious users would just clean it back out again.
We may end up with a situation where only a few people internal to OpenAI know how the watermark works, and they occasionally answer questions for law enforcement with the proper paperwork.
AmputatorBot t1_j5eqn8m wrote
Reply to comment by abriec in [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
It looks like you shared an AMP link. These should load faster, but AMP is controversial because of concerns over privacy and the Open Web.
Maybe check out the canonical page instead: https://techcrunch.com/2022/12/10/openais-attempts-to-watermark-ai-text-hit-limits/
^(I'm a bot | )^(Why & About)^( | )^(Summon: u/AmputatorBot)
abriec t1_j5eqmbt wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
I believe there’s ongoing work related to this at OpenAI and similar research in generative models in general, like this submission currently under review.
JackandFred t1_j5epyi0 wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
It wouldn’t necessarily be easy. But you say you want one detectable by some “key or other model” you can already design or use a model to detect if it was generated by Gpt, so it wouldn’t really need to use a watermark if you’re using a model. And if you’re using a more traditional watermark for digital pictures it could be very easily removed.
sabertoothedhedgehog t1_j5eneoh wrote
Reply to ChatGPT is not all you need [R] by EduCGM
Love the topic of the paper.Absolutely HATE the figures showing taxonomies / example AI tools. These visualisations with boxes and arrows are really awful. These arrows are all over the place and meaningless. And the category boxes look the same as the application boxes.
It could have looked more like this:https://the-decoder.com/wp-content/uploads/2022/10/market_map_generative_AI-770x1027.png.webp
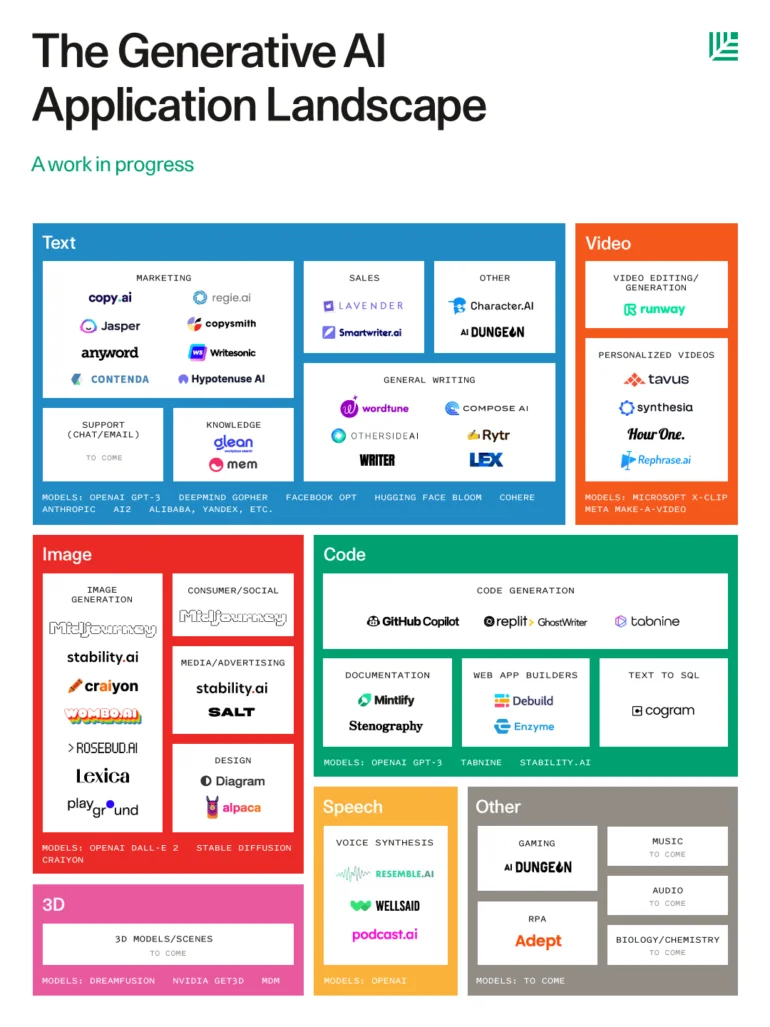{kind=link}
Or like this:https://www.sequoiacap.com/wp-content/uploads/sites/6/2022/09/genai-landscape-8.png
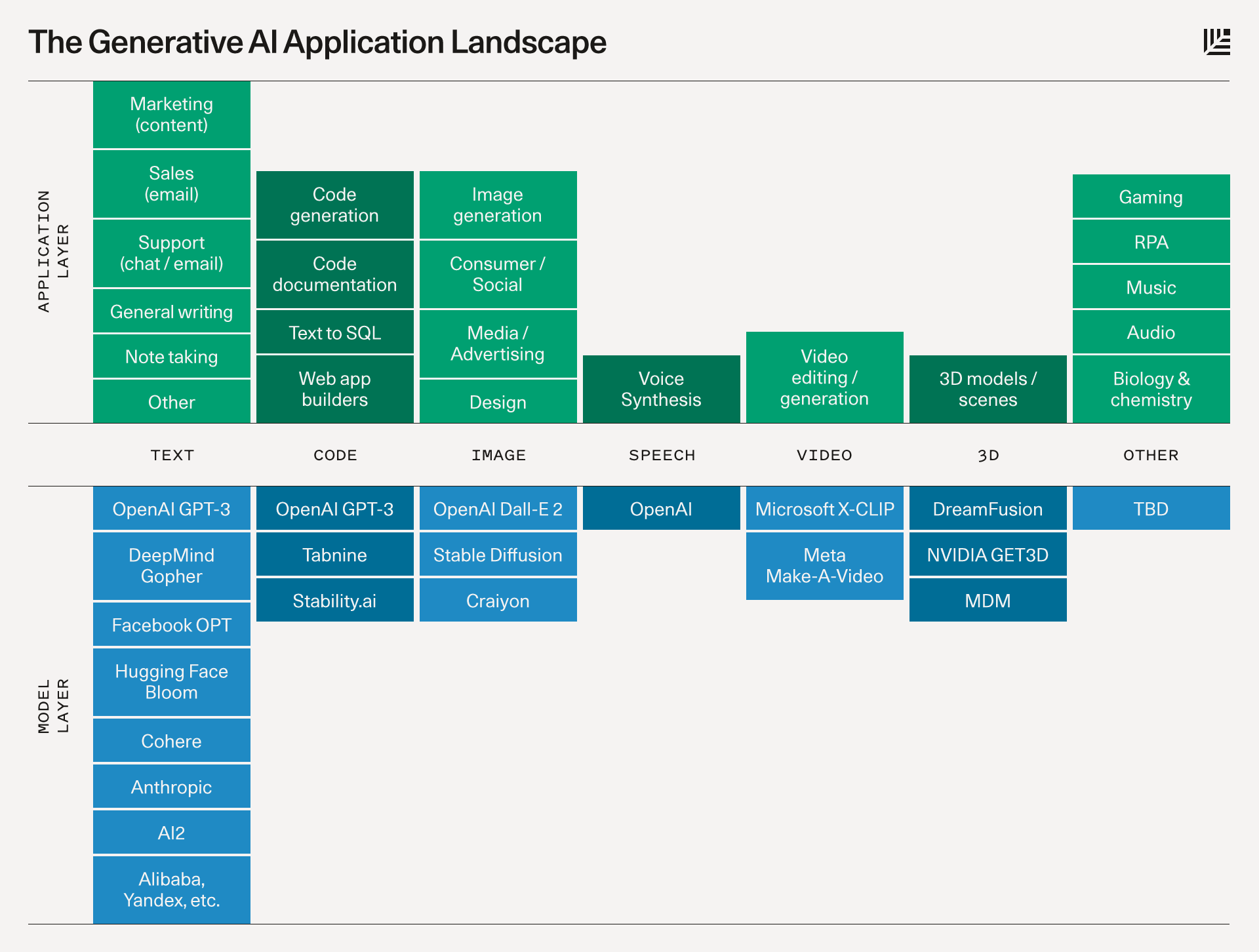{kind=link}
I don't even particularly like my examples. But there is no need for all these arrows and category boxes looking like the examples.
SatoshiNotMe t1_j5emmmu wrote
Reply to comment by Veggies-are-okay in [R] Is there a way to combine a knowledge graph and other types of data for ML purposes? by Low-Mood3229
This great survey/intro on GNN was just published this week
https://papers.labml.ai/paper/050c8888986f11ed8f9c3d8021bca7c8
clemda2 t1_j5eliix wrote
Reply to [D] GCN datasets by ramya_1995
You CAN batch train GCNs (or some of them are very amenable to that) some of the most scalable GCNs rely on something like GraphSAGE convolution which doesn’t require the whole graph laplacian for updates (this approach is used by Wikipedia, Uber, Pinterest) to train highly scalable GCNs). Other convolutional operators like GAT also can be batch trained.
You can use the Python package PyTorch-Geometric documentation as a jumping off point for reading about practical graph sub sampling.
olegranmo OP t1_j5eiya9 wrote
Reply to comment by hiptobecubic in [R] New Tsetlin machine learning scheme creates up to 80x smaller logical rules, benefitting hardware efficiency and interpretability. by olegranmo
First chapter of An Introduction to Tsetlin Machines is a great place to start: https://tsetlinmachine.org
hiptobecubic t1_j5eik7j wrote
Reply to [R] New Tsetlin machine learning scheme creates up to 80x smaller logical rules, benefitting hardware efficiency and interpretability. by olegranmo
Is there a canonical introductory paper on TMs?
ikke89 t1_j5egvtc wrote
Reply to ChatGPT is not all you need [R] by EduCGM
Thanks, I've been looking for an overview like that for a while!
ardula99 t1_j5e9in9 wrote
Reply to comment by MonsieurBlunt in ChatGPT is not all you need [R] by EduCGM
Yeah, I couldn't understand what this sentence means either.
damc4 t1_j5e9bog wrote
Reply to comment by gunshoes in [D]Can a bachelor get a job in ML? by alphapussycat
Ok, so that proves that someone has the skill. But when someone doesn't have master/phd, that doesn't prove that someone doesn't have that skill. In other words, if someone has no master/phd degree, but has published a research paper, then they have also proved to have that skill, so it should be possible for someone with bachelor / no bachelor to get a job in ML. Is that correct?
JustARandomNoob165 t1_j5e4vke wrote
Reply to comment by IamTimNguyen in [R] Greg Yang's work on a rigorous mathematical theory for neural networks by IamTimNguyen
I know it is a very broad question, but maybe you have recommendation of materials/resources to prepare yourself better to digest the topics used in this talk? Thank you in advance very much!
chaoticneutralchick t1_j5e43ie wrote
Reply to ChatGPT is not all you need [R] by EduCGM
I suppose, if you’re focused on using it as a tool!
Cherubin0 t1_j5e3xrr wrote
Reply to [R] New Tsetlin machine learning scheme creates up to 80x smaller logical rules, benefitting hardware efficiency and interpretability. by olegranmo
So time to dump deep learning for tm?
Trappster t1_j5e3jdt wrote
Reply to ChatGPT is not all you need [R] by EduCGM
Great summary! You made a mistake with the corgi in the Sushi house description. You also used it in the following picture (Times Square)
Beautiful-Section-42 t1_j5e0dg1 wrote
Reply to comment by [deleted] in ChatGPT is not all you need [R] by EduCGM
Sir you didn't understand the comment. Read it again
dineNshine t1_j5esx4f wrote
Reply to [D] Couldn't devs of major GPTs have added an invisible but detectable watermark in the models? by scarynut
Why would you want to do this? We can fake text without GPT, and we also have the means to prove authenticity by digital signatures. By limiting the technology artificially, you will end up limiting the end user, while organizations with more resources will still be able to circumvent these limitations by training their own models.
To avoid limiting usability, desired limitations should be applied on top of the base model by the end user, not to the base model itself.
The sole consequence of attempts like which OP suggests is further centralization of the technology, which is the worst imaginable result.